Turbo2K: Towards Ultra-Efficient and High-Quality 2K Video Synthesis
* Equal contribution # Corresponding author
Overview
Demand for 2K video synthesis is growing alongside rising expectations for ultra-clear visuals. While diffusion transformers (DiTs) excel at high-quality video generation, scaling them to 2K resolution is computationally expensive due to quadratic memory and processing costs.
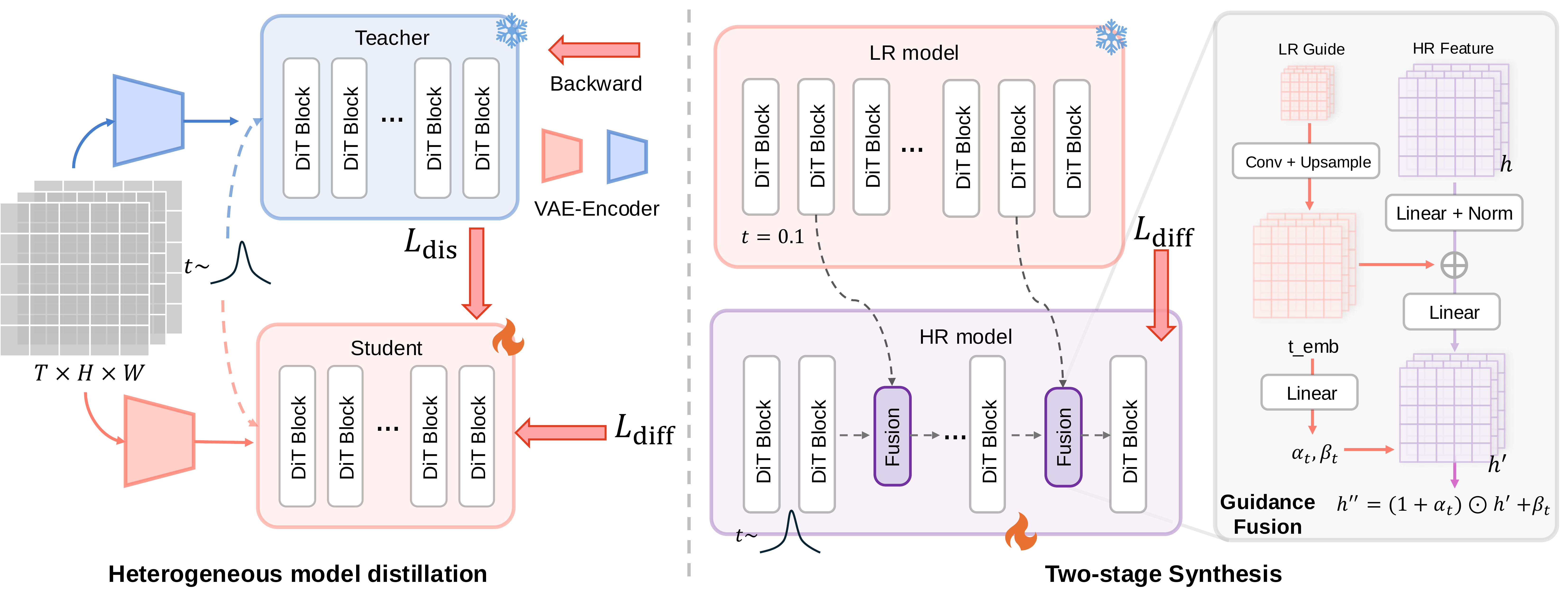
We present Turbo2K, an efficient framework for detail-rich 2K video generation with significantly improved training and inference efficiency. Turbo2K operates in a highly compressed latent space, drastically reducing computational demands. To compensate for compression-induced quality loss and limited model capacity, we employ a knowledge distillation strategy, enabling a lightweight student model to inherit the generative power of a larger teacher model. Despite architectural and latent-space differences, we observe strong alignment in DiTs' internal representations, supporting effective knowledge transfer.
Additionally, we introduce a two-stage synthesis pipeline: low-resolution multi-level features are generated first, then used to guide high-resolution video synthesis. This ensures structural coherence, fine-grained detail, and eliminates redundant encoding-decoding steps.
Turbo2K achieves compelling efficiency , generating 5-second, 24fps 2K videos up to 20× faster than existing methods, making scalable, high-resolution video generation practical for real-world applications.

Text‑to‑Video
Contact Us
Feel free to contact Wenbo Li at fenglinglwb@gmail.com for cooperation, communication, or applying internships.