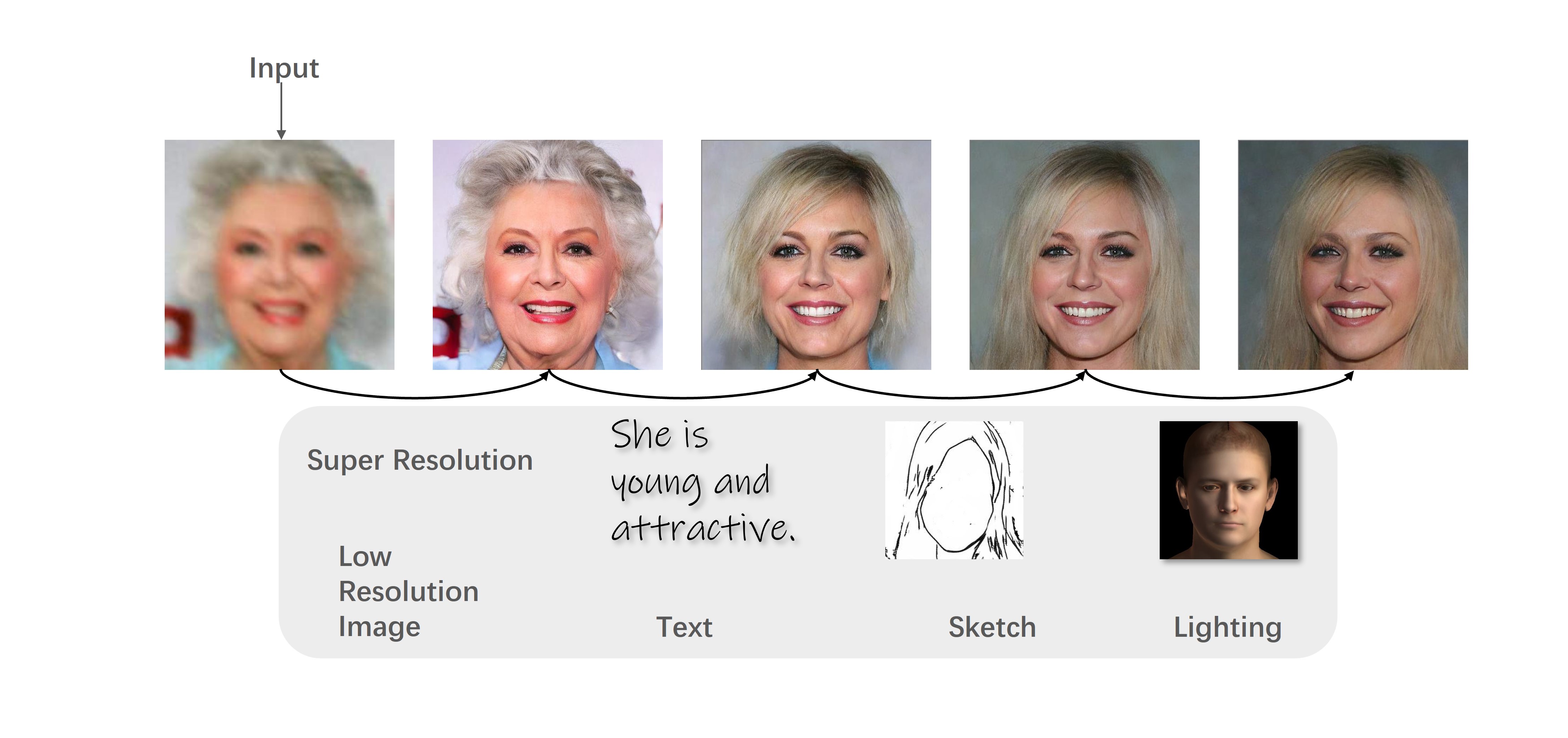
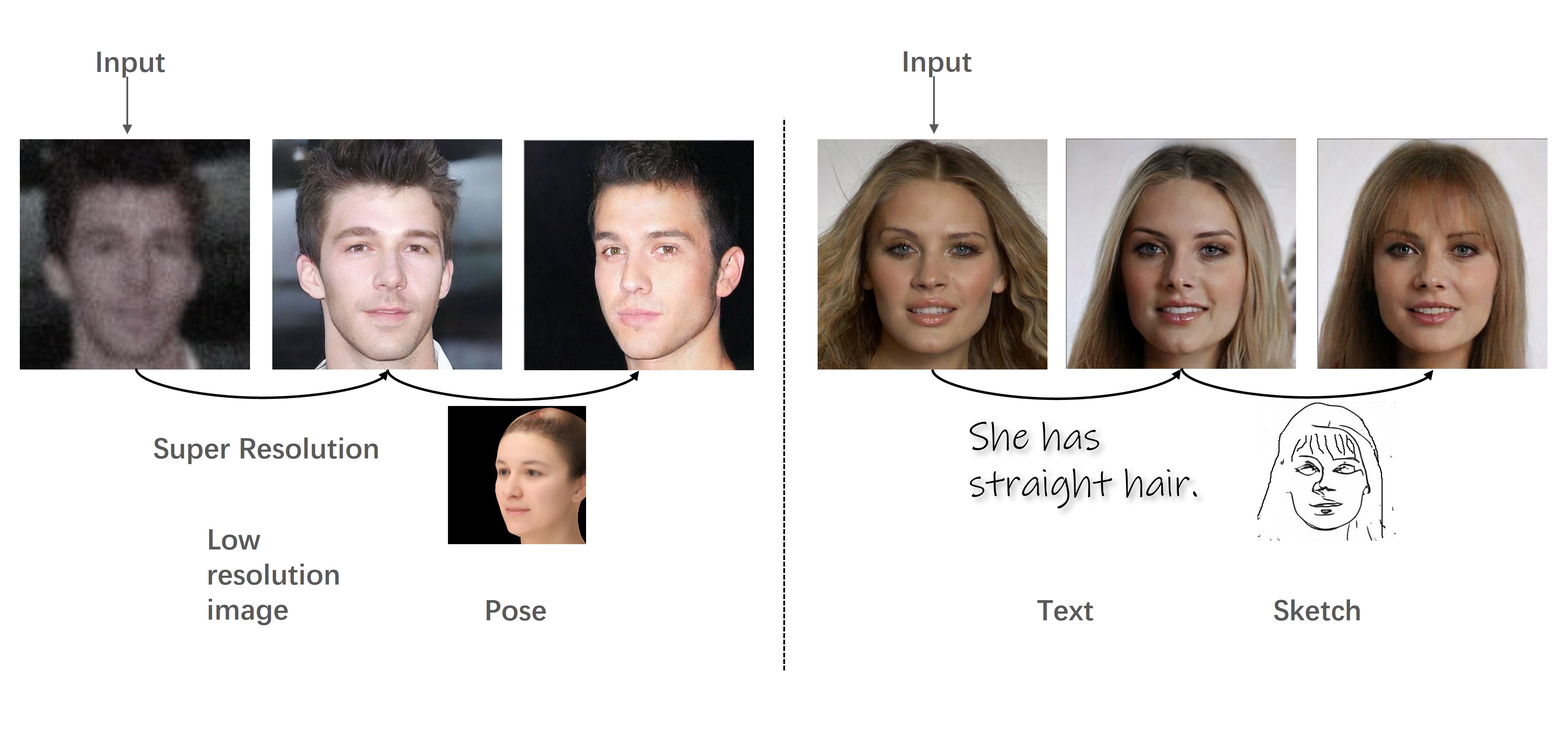
Recent progress in multi-modal conditioned face synthesis has enabled the creation of visually striking and accurately aligned facial images.
Yet, current methods still face issues with scalability, limited flexibility, and a one-size-fits-all approach to control strength, not accounting for the differing levels of conditional entropy, a measure of unpredictability in data given some condition, across modalities.
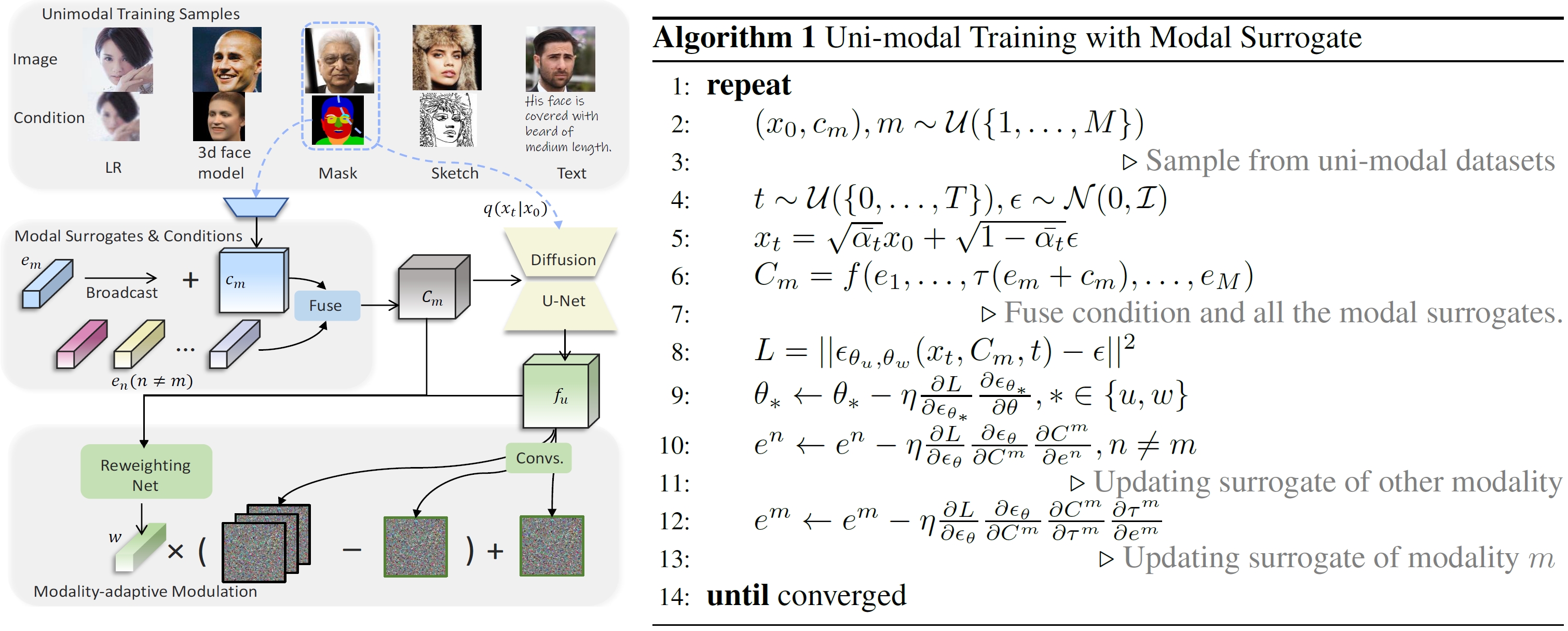
To address these challenges, we introduce a novel uni-modal training approach with modal surrogates, coupled with an entropy-aware modal-adaptive modulation, to support flexible, scalable, and scalable multi-modal conditioned face synthesis network.
Our uni-modal training with modal surrogate that only leverage uni-modal data, use modal surrogate to decorate condition with modal-specific characteristic and serve as linker for inter-modal collaboration , fully learns each modality control in face synthesis process as well as inter-modal collaboration.
The entropy-aware modal-adaptive modulation finely adjust diffusion noise according to modal-specific characteristics and given conditions, enabling well-informed step along denoising trajectory and ultimately leading to synthesis results of high fidelity and quality.
Our framework improves multi-modal face synthesis under various conditions, surpassing current methods in image quality and fidelity, as demonstrated by our thorough experimental results.